Quorum Queues
Overview
The RabbitMQ quorum queue is a modern queue type which implements a durable, replicated queue based on the Raft consensus algorithm and should be considered the default choice when needing a replicated, highly available queue.
Quorum queues are designed for data safety as well as reliable and fast leader election properties that ensure high availability even during upgrades or other turbulence.
Certain use cases fit quorum queues better than others and it is important to be aware of these when designing systems.
There are some differences in behaviour compared to classic queues as well as some limitations that it is important to consider when converting from an application using classic queues.
Some new features are specific to quorum queues such as poison message handling,
at least once dead-lettering,
delayed retry, consumer timeouts,
and the ability to annotate a message using the modified outcome when using AMQP.
Quorum queues and streams are the two replicated data structures available. Classic queue mirroring was removed starting with RabbitMQ 4.0.
Topics Covered
Topics covered in this document include:
- Primary use cases of quorum queues and when not to use them
- How are quorum queues different from classic queues
- How to declare a quorum queue
- Replication-related topics: member management, leader rebalancing, optimal number of members, etc
- What guarantees quorum queues offer in terms of leader failure handling, data safety and availability
- Continuous Membership Reconciliation
- The additional dead lettering features supported by quorum queues
- Strict message priorities for message ordering and delivery
- Consumer timeouts for handling slow or stuck consumers
- Delayed retry mechanism for message redelivery with backoff
- Memory and disk footprint of quorum queues
- Performance characteristics of quorum queues
- Performance tuning for optimal quorum queue operation
- Poison message handling (failure-redelivery loop protection)
- Migrating from Mirrored Classic Queues
- Options to Relax Property Equivalence
- Configurable settings of quorum queues
and more.
General familiarity with RabbitMQ clustering would be helpful here when learning more about quorum queues.
What is a Quorum?
A quorum in a distributed system can
be defined as an agreement between a majority of members ((N/2)+1 where N is the total number of
system participants).
When applied to queue replication in RabbitMQ clusters it means that the majority of queue members (leader and followers) agree on the exact state of the queue and its contents.
Use Cases
Quorum queues are not designed to be used for every use case that requires a queue.
The intended use of quorum queues is in topologies where queues typically exist for a long time, need high availability and are critical to certain aspects of an application's architecture.
Examples of good use cases would be incoming orders in a sales system or votes cast in an electoral system where potentially losing messages would have a significant impact on overall system correctness and function.
Stock tickers, instant messaging systems and RPC reply queues benefit less or not at all from use of quorum queues.
For use cases that need replication and repeatable reads (e.g. fan-out notifications), streams may be a better option than quorum queues.
There are no hard limitations on the number of quorum queues that a system can sustain. However, if a use case requires more than ~5000 quorum queues it is recommended to review the topology and see if some quorum queues can be replaced with either classic queues or streams.
Upgrade and failure testing is always recommended irrespective of the number of quorum queues in the system.
Publishers should use publisher confirms as this is how clients can interact with the quorum queue consensus system. Publisher confirms will only be issued once a published message has been successfully replicated to a quorum of members and is considered "safe" within the context of the queue.
Consumers should use manual acknowledgements to ensure messages that aren't successfully processed are returned to the queue so that another consumer can re-attempt processing.
When Not to Use Quorum Queues
In some cases quorum queues should not be used. They typically involve:
- Temporary queues: transient or exclusive queues, high queue churn (declaration and deletion rates)
- Lowest possible latency: the underlying consensus algorithm has an inherently higher latency due to its data safety features
- When data safety is not a priority (e.g. applications do not use manual acknowledgements and publisher confirms are not used)
- Very long queue backlogs (5M+ messages) (streams are likely to be a better fit)
- Large fanouts: (streams are likely to be a better fit)
Features
Quorum queues share most of the fundamentals with other queue types.
Comparison with Classic Queues
The following operations work the same way for quorum queues as they do for classic queues:
- Consumption, consumer registration
- Consumer acknowledgements (except for global QoS and prefetch)
- Consumer cancellation
- Purging
- Deletion
With some queue operations there are minor differences:
- Declaration
- Setting prefetch for consumers
Feature Matrix
| Feature | Classic queues | Quorum queues |
|---|---|---|
| Non-durable queues | yes | no |
| Message replication | no | yes |
| Exclusivity | yes | no |
| Per message persistence | per message | always |
| Membership changes | no | semi-automatic |
| Message TTL (Time-To-Live) | yes | yes |
| Queue TTL | yes | partially (lease is not renewed on queue re-declaration) |
| Queue length limits | yes | yes (except x-overflow: reject-publish-dlx) |
| Keeps messages in memory | see Classic Queues | never (see Resource Use) |
| Message priority | yes | yes, strict |
| Single Active Consumer | yes | yes |
| Consumer exclusivity | yes | no (use Single Active Consumer) |
| Consumer priority | yes | yes |
| Dead letter exchanges | yes | yes |
| Adheres to policies | yes | yes (see Policy support) |
| Poison message handling | no | yes |
| Consumer timeout | no | yes |
| Delayed retry | no | yes |
| Server-named queues | yes | no |
Modern quorum queues also offer higher throughput and less latency variability for many workloads.
Queue and Per-Message TTL
Quorum queues support both Queue TTL and message TTL (including Per-Queue Message TTL in Queues and Per-Message TTL in Publishers). When using any form of message TTL, the memory overhead increases by 16 bytes per message.
Length Limit
Quorum queues has support for queue length limits.
The drop-head and reject-publish overflow behaviours are supported but they
do not support reject-publish-dlx configurations as Quorum queues take a different
implementation approach than classic queues.
The current implementation of reject-publish overflow behaviour does not strictly
enforce the limit and allows a quorum queue to overshoot its limit by at least
one message, therefore it should be taken with care in scenarios where a precise
limit is required.
When a quorum queue reaches the max-length limit and reject-publish is configured
it notifies each publishing channel who from thereon will reject all messages back to
the client. This means that quorum queues may overshoot their limit by some small number
of messages as there may be messages in flight whilst the channels are notified.
The number of additional messages that are accepted by the queue will vary depending
on how many messages are in flight at the time.
Dead Lettering
Quorum queues support dead lettering via dead letter exchanges (DLXs).
Traditionally, using DLXs in a clustered environment has not been safe.
Quorum queues support a safer form of dead-lettering that uses
at-least-once guarantees for the message transfer between queues
(with the limitations and caveats outlined below).
This is done by implementing a special, internal dead-letter consumer process that works similarly to a normal queue consumer with manual acknowledgements apart from it only consumes messages that have been dead-lettered.
This means that the source quorum queue will retain the
dead-lettered messages until they have been acknowledged. The internal consumer
will consume dead-lettered messages and publish them to the target queue(s) using
publisher confirms. It will only acknowledge once publisher confirms have been
received, hence providing at-least-once guarantees.
at-most-once remains the default dead-letter-strategy for quorum queues and is useful for scenarios
where the dead lettered messages are more of an informational nature and where it does not matter so much
if they are lost in transit between queues or when the overflow
configuration restriction outlined below is not suitable.
Activating at-least-once Dead-Lettering
To activate or turn on at-least-once dead-lettering for a source quorum queue, adapt the policy
that enables dead lettering like so:
- Set
dead-letter-strategytoat-least-once(default isat-most-once). - Set
overflowtoreject-publish(default isdrop-head). - Configure a
dead-letter-exchange - Enable the
stream_queuefeature flag in case it is not enabled
It is recommended to additionally configure max-length or max-length-bytes
to prevent excessive message buildup in the source quorum queue (see caveats below).
Optionally, configure a dead-letter-routing-key.
Limitations
at-least-once dead lettering does not work with the default drop-head overflow
strategy even if a queue length limit is not set.
Hence if drop-head is configured the dead-lettering will fall back
to at-most-once. Use the overflow strategy reject-publish instead.
Caveats
at-least-once dead-lettering will require more system resources such as memory and CPU.
Therefore, turn on at-least-once only if dead lettered messages should not be lost.
at-least-once guarantees opens up some specific failure cases that needs handling.
As dead-lettered messages are now retained by the source quorum queue until they have been
safely accepted by the dead-letter target queue(s) this means they have to contribute to the
queue resource limits, such as max length limits so that the queue can refuse to accept
more messages until some have been removed. Theoretically it is then possible for a queue
to only contain dead-lettered messages, in the case where, say a target dead-letter
queue isn't available to accept messages for a long time and normal queue consumers
consume most of the messages.
Dead-lettered messages are considered "live" until they have been confirmed by the dead-letter target queue(s).
There are few cases for which dead lettered messages will not be removed from the source queue in a timely manner:
- The configured dead-letter exchange does not exist.
- The messages cannot be routed to any queue (equivalent to the
mandatorymessage property). - One (of possibly many) routed target queues does not confirm receipt of the message. This can happen when a target queue is not available or when a target queue rejects a message (e.g. due to exceeded queue length limit).
The dead-letter consumer process will retry periodically if either of the scenarios above occur which means there is a possibility of duplicates appearing at the DLX target queue(s).
For each quorum queue with at-least-once dead-lettering turned on, there will be one internal dead-letter
consumer process. The internal dead-letter consumer process is co-located on the quorum queue leader node.
It keeps all dead-lettered message bodies in memory.
It uses a prefetch size of 32 messages to limit the amount of message bodies kept in memory if no confirms
are received from the target queues.
That prefetch size can be increased by the dead_letter_worker_consumer_prefetch setting in the rabbit app section of the
advanced config file if high dead-lettering throughput
(thousands of messages per second) is required.
For a source quorum queue, it is possible to switch dead-letter strategy dynamically from at-most-once
to at-least-once and vice versa. If the dead-letter strategy is changed either directly
from at-least-once to at-most-once or indirectly, for example by changing overflow from reject-publish
to drop-head, any dead-lettered messages that have not yet been confirmed by all target queues will be deleted.
Messages published to the source quorum queue are persisted on disk regardless of the message delivery mode (transient or persistent). However, messages that are dead lettered by the source quorum queue will keep the original message delivery mode. This means if dead lettered messages in the target queue should survive a broker restart, the target queue must be durable and the message delivery mode must be set to persistent when publishing messages to the source quorum queue.
Consumer Priorities
Quorum queues support consumer priorities.
Message Priorities
Strict message priority support for quorum queues is available as of RabbitMQ 4.3.
Starting with RabbitMQ 4.3, quorum queues implement strict priority support with 32 priority levels (0-31): higher priority messages are dispatched ahead of lower priority ones, subject to consumer prefetch and to the returned messages exception described below. Earlier versions mapped priorities onto two internal buckets (normal and high) with a 2:1 dispatch ratio.
Priorities are clamped to the 0-31 range. Messages without a priority property are treated as priority 4 (classic queues default to 0).
Priorities Are Always Enabled
Quorum queues always provide the full 0-31 priority range. There is no opt-in argument: x-max-priority applies only to classic queues and is ignored by quorum queues.
Using the Java client:
Channel ch = ...;
Map<String, Object> args = new HashMap<String, Object>();
// quorum queues always support priorities; no extra argument needed
args.put("x-queue-type", "quorum");
ch.queueDeclare("my-quorum-queue", true, false, false, args);
Publishers set message priority the same way as for classic queues: via the priority field of basic.properties, with larger numbers indicating higher priority.
Per-Priority Message Counts
Each priority level maintains separate message counts that are visible in the Management UI. This allows operators to monitor queue depth per priority and ensure that high-priority messages are not getting stuck behind lower-priority ones.
Redelivery of Returned Messages
When messages are returned to the queue (via reject, nack, or modify), they do not retain their original priority. Instead, they are added to the returns queue and are requeued in the exact order they were returned, regardless of their priority.
Priority-Aware Message Expiration
Message expiration (TTL) scans run across all priority levels, ensuring that messages expire in the correct order regardless of their priority level. For each priority level, the scan will only process messages until it encounters the first unexpired message. This prevents low-priority messages from blocking the expiration of high-priority messages that have exceeded their TTL.
Consumer Timeout
Consumer timeout support for quorum queues is available as of RabbitMQ 4.3.
Quorum queues support configurable consumer timeouts to handle slow or stuck consumers. When a consumer holds unacknowledged messages beyond the configured timeout period, the messages are automatically returned to the queue and become available for redelivery by another consumer.
How It Works
When a consumer timeout fires:
-
For AMQP 1.0 clients: The broker sends a
DISPOSITIONframe withstate=releasedinstead of detaching the link. This allows the client to auto-settle the delivery and potentially recover without needing to re-establish the link. Until the consumer settles the timed out message it will not be assigned any further messages. -
For AMQP 0.9.1 clients: The consumer is cancelled (if the client supports the
consumer_cancel_notifycapability), otherwise the channel is closed with aprecondition_failederror. In both cases, the messages are returned to the queue for redelivery. -
For MQTT clients: The consumer subscription is ended and messages are returned to the queue.
This graceful handling (especially for AMQP 1.0) provides better reliability and reduces connection thrashing compared to forcefully closing the link.
Configuration Options
Consumer timeout can be configured at the consumer level, queue level, or globally:
Consumer Attach Property (AMQP 1.0)
rabbitmq:consumer-timeout
Consumer Argument (AMQP 0.9.1)
x-consumer-timeout
Set when creating a consumer to apply the timeout only to that consumer.
Queue Argument
x-consumer-timeout
Set when declaring a queue to apply to all consumers of that queue.
Policy Key
consumer-timeout
Apply a consumer timeout to all queues matching a pattern.
Global Setting
In rabbitmq.conf:
consumer_timeout = 1800000
The timeout value is specified in milliseconds.
Disconnected Consumer Node Timeout
When a consumer's node becomes unreachable due to a network partition, quorum queues will wait a configurable period before returning messages held by that consumer. This is controlled by the consumer_disconnected_timeout setting:
Policy Key
consumer-disconnected-timeout
Global Setting
In rabbitmq.conf:
consumer_disconnected_timeout = 60000
Default is 60 seconds (60000 milliseconds).
Queue Argument
x-consumer-disconnected-timeout
Management UI and Monitoring
The Management UI displays:
- Consumer timeout status for each outgoing link (highlighted in yellow when active)
- Disconnected consumer state
- Helpful tooltips explaining the consumer timeout feature
Warnings are logged when a consumer timeout occurs, including:
- Connection name
- Link name and handle
- AMQP container ID
- Queue name
Delayed Retry
Delayed retry support for quorum queues is available as of RabbitMQ 4.3.
Quorum queues support configurable delayed retry with linear back-off for messages that are returned to the queue. When a message is rejected, nacked, or modified by a consumer, it can be held in a delayed state before becoming available for redelivery. This helps prevent rapid retry loops and implements linear back-off strategies.
How It Works
When a message is returned and delayed retry is enabled, the message is held in a delayed queue keyed by its ready-at timestamp. The delay is calculated based on the message's delivery count:
delay = min(min_delay * delivery_count, max_delay)
For example, with min_delay=1000ms and max_delay=30000ms:
- First return: 1000ms delay
- Second return: 2000ms delay
- Third return: 3000ms delay
- Fourth return and beyond: 30000ms delay (capped at max_delay)
NB: a message's delivery-count is only incremented for failures
(session/channel crashes and using the modified outcome with delivery_failed=true).
This means not all return types will cause the message to be delayed longer than
the minimum.
Configuration Options
Delayed retry can be configured via queue arguments (at declaration time), queue policies, or both.
Queue Arguments
Queue arguments can be set when declaring a queue using AMQP 0.9.1:
x-delayed-retry-type- Retry type:disabled,all,failed, orreturned(default:disabled)x-delayed-retry-min- Minimum delay in milliseconds (required if enabled)x-delayed-retry-max- Maximum delay in milliseconds (optional)
Policy Keys
Policies provide a way to configure delayed retry across multiple queues:
delayed-retry-type- Retry type:disabled,all,failed, orreturneddelayed-retry-min- Minimum delay in millisecondsdelayed-retry-max- Maximum delay in milliseconds
Retry Types
disabled- Delayed retry is not applied (default)all- All returned messages are delayed, regardless of whether the delivery count was incrementedfailed- Only messages with incrementeddelivery-countare delayed (e.g., viareject, AMQP 1.0modifywithdelivery_failed=true, or channel termination with pending messages)returned- Only messages without incrementeddelivery-countare delayed (e.g., vianackor AMQP 1.0modifywithdelivery_failed=false)
Example Configuration
- bash
- HTTP API
- Management UI
rabbitmqctl set_policy qq-delayed-retry \
"^critical\." \
'{"delayed-retry-type": "all", "delayed-retry-min": 1000, "delayed-retry-max": 30000}' \
--priority 10 \
--apply-to "quorum_queues"
PUT /api/policies/%2f/qq-delayed-retry
{"pattern": "^critical\.",
"definition": {
"delayed-retry-type": "all",
"delayed-retry-min": 1000,
"delayed-retry-max": 30000
},
"priority": 10,
"apply-to": "quorum_queues"}
- Navigate to
Admin>Policies>Add / update a policy - Enter policy name, pattern, and select
quorum_queuesas the apply-to type Add policy arguments:
delayed-retry-type=alldelayed-retry-min=1000delayed-retry-max=30000
- Click
Add policy
Advanced Features
Explicit Delivery Time
The x-opt-delivery-time annotation can be set on message properties to specify an explicit future delivery time (in milliseconds since epoch). This annotation is only available when using the AMQP modify outcome and takes precedence over the calculated linear back-off delay.
Management UI and Monitoring
Delayed retry configuration, deferred message counts, and retry status are displayed in the Management UI, allowing operators to:
- View delayed retry configuration for each queue
- Monitor the number of delayed messages per queue
- Identify queues with excessive message delays
Poison Message Handling
Quorum queue support handling of poison messages, that is, messages that cause a consumer to repeatedly requeue a delivery (possibly due to a consumer failure) such that the message is never consumed completely and positively acknowledged so that it can be marked for deletion by RabbitMQ.
Quorum queues keep track of the number of unsuccessful (re)delivery attempts and expose it in the "x-delivery-count" header that is included with any redelivered message.
Starting with RabbitMQ 4.3, the delivery limit is based on delivery-count rather
than acquired-count. This means that unlimited explicit message returns
(via nack or AMQP 1.0 modify with delivery_failed=false) are now allowed
without counting towards the delivery limit. The header x-acquired-count has
been introduced to track the number of times a message was acquired by a consumer,
alongside x-delivery-count which tracks the actual number of failed deliveries.
x-acquired-count is the recommended header for tracking the number of times a
message has been assigned to a consumer.
It provides more accurate information about the potential number of times
a message may have been seen by a consumer. Note that
this counter is incremented when a message is assigned to a consumer. This does
not mean that a consumer has actually ever seen the message.
When a message has been redelivered more times than the limit the message will be dropped (removed) or dead-lettered (if a DLX is configured).
For consumers with a prefetch greater than 1, all outstanding unacknowledged deliveries can be discarded by this mechanism if they all were requeued as a group multiple times, due to, say, consumer application instance failures.
It is recommended that all quorum queues have a dead letter configuration of some sort to ensure messages aren't dropped and lost unintentionally. Using a single stream for a low priority dead letter policy is a good, low resource way to ensure dropped messages are retained for some time after.
Starting with RabbitMQ 4.0, the delivery limit for quorum queues defaults to 20.
The 3.13.x era behavior where there was no limit can be restored by setting x-delivery-limit=-1
optional queue argument when declaring a queue.
This is not recommended.
When is delivery count incremented?
| Trigger | acquired-count gets incremented | delivery-count gets incremented (delivery attempt failed) |
|---|---|---|
AMQP 1.0 released disposition | ✅ | ❌ |
AMQP 1.0 rejected disposition | ✅ | ✅ |
AMQP 1.0 modified disposition with delivery-failed=false | ✅ | ❌ |
AMQP 1.0 modified disposition with delivery-failed=true | ✅ | ✅ |
AMQP 0.9.1 basic.nack | ✅ | ❌ |
AMQP 0.9.1 basic.reject | ✅ | ✅ |
| Client crash / Connection loss | ✅ | ✅ |
| Intra-cluster network partition (consumer node suspected down) | ✅ | ❌ |
| Consumer timeout (consumer doesn't ack in time) | ✅ | ❌ |
Configuring the Limit
It is possible to set a delivery limit for a queue using a policy
argument, delivery-limit.
The value of -1 disables the limit altogether. It is not recommended that users
disable this limit as repeated requeues can threaten the stability of a queue or
RabbitMQ cluster.
Note that since 4.3 the delivery count (against which the delivery limit is evaluated)
will only be incremented for genuine failures such as session/channel crashes or
when using the modified outcome with delivery-failed=true or basic.reject in
AMQP 0.9.1.
Overriding the Limit
The following example sets the limit to 50 for queues whose names begin with
qq.
- bash
- PowerShell
- HTTP API
- Management UI
rabbitmqctl set_policy qq-overrides \
"^qq\." '{"delivery-limit": 50}' \
--priority 123 \
--apply-to "quorum_queues"
rabbitmqctl.bat set_policy qq-overrides ^
"^qq\." "{""delivery-limit"": 50}" ^
--priority 123 ^
--apply-to "quorum_queues"
PUT /api/policies/%2f/qq-overrides
{"pattern": "^qq\.",
"definition": {"delivery-limit": 50},
"priority": 1,
"apply-to": "quorum_queues"}
Navigate to
Admin>Policies>Add / update a policy.Enter a policy name (such as "qq-overrides") next to Name, a pattern (such as "^qq.") next to Pattern, and select what kind of entities (quorum queues in this example) the policy should apply to using the
Apply todrop down.Enter "delivery-limit" for policy argument and 50 for its value in the first line next to
Policy.Click
Add policy.
Disabling the Limit
The following example disables the limit for queues whose names begin with
qq.unlimited.
- bash
- PowerShell
- HTTP API
- Management UI
rabbitmqctl set_policy qq-overrides \
"^qq\.unlimited" '{"delivery-limit": -1}' \
--priority 123 \
--apply-to "quorum_queues"
rabbitmqctl.bat set_policy qq-overrides ^
"^qq\.unlimited" "{""delivery-limit"": -1}" ^
--priority 123 ^
--apply-to "quorum_queues"
PUT /api/policies/%2f/qq-overrides
{"pattern": "^qq\.unlimited",
"definition": {"delivery-limit": -1},
"priority": 1,
"apply-to": "quorum_queues"}
Navigate to
Admin>Policies>Add / update a policy.Enter a policy name (such as "qq-overrides") next to Name, a pattern (such as "^qq.unlimited") next to Pattern, and select what kind of entities (quorum queues in this example) the policy should apply to using the
Apply todrop down.Enter "delivery-limit" for policy argument and -1 for its value in the first line next to
Policy.Click
Add policy.
Configuring the Limit and Setting Up Dead-Lettering
Messages that are redelivered more times than the limit allows for will be either dropped (removed) or dead-lettered.
The following example configures both the limit and an exchange to dead-letter (republish) such messages. The target exchange in this example is called "redeliveries.limit.dlx". Declaring it and setting up its topology (binding queues and/or streams to it) is not covered in this example.
- bash
- PowerShell
- HTTP API
- Management UI
rabbitmqctl set_policy qq-overrides \
"^qq\." '{"delivery-limit": 50, "dead-letter-exchange": "redeliveries.limit.dlx"}' \
--priority 123 \
--apply-to "quorum_queues"
rabbitmqctl.bat set_policy qq-overrides ^
"^qq\." "{""delivery-limit"": 50, ""dead-letter-exchange"": ""redeliveries.limit.dlx""}" ^
--priority 123 ^
--apply-to "quorum_queues"
PUT /api/policies/%2f/qq-overrides
{"pattern": "^qq\.",
"definition": {"delivery-limit": 50, "dead-letter-exchange": "redeliveries.limit.dlx"},
"priority": 1,
"apply-to": "quorum_queues"}
Navigate to
Admin>Policies>Add / update a policy.Enter a policy name (such as "qq-overrides") next to Name, a pattern (such as "^qq.") next to Pattern, and select what kind of entities (quorum queues in this example) the policy should apply to using the
Apply todrop down.Enter "delivery-limit" for policy argument and 50 for its value in the first line next to
Policy, then "dead-letter-exchange" for the second key and "redeliveries.limit.dlx" for its value.Click
Add policy.
To learn more about dead-lettering, please consult its dedicated guide.
Policy Support
Quorum queues can be configured via RabbitMQ policies. The below table summarises the policy keys they adhere to.
| Definition Key | Type |
|---|---|
max-length | Number |
max-length-bytes | Number |
overflow | "drop-head" or "reject-publish" |
expires | Number (milliseconds) |
dead-letter-exchange | String |
dead-letter-routing-key | String |
delivery-limit | Number |
delayed-retry-type | "disabled", "all", "failed", or "returned" |
delayed-retry-min | Number (milliseconds) |
delayed-retry-max | Number (milliseconds) |
consumer-timeout | Number (milliseconds) |
consumer-disconnected-timeout | Number (milliseconds) |
Features that are not Supported
Transient (non-Durable) Queues
Classic queues can be non-durable. Quorum queues are always durable per their assumed use cases.
Exclusivity
Exclusive queues are tied to the lifecycle of their declaring connection. Quorum queues by design are replicated and durable, therefore the exclusive property makes no sense in their context. Therefore quorum queues cannot be exclusive.
Quorum queues are not meant to be used as temporary queues.
Global QoS
Quorum queues do not support global QoS prefetch where a channel sets a single prefetch limit for all consumers using that channel. If an attempt is made to consume from a quorum queue from a channel with global QoS activated a channel error will be returned.
Use per-consumer QoS prefetch, which is the default in several popular clients.
Usage
Quorum queues share most of the fundamentals with other queue types. Any AMQP 0.9.1 client library that can specify optional queue arguments when declaring will be able to use quorum queues.
First we will cover how to declare a quorum queue using AMQP 0.9.1.
Declaring
To declare a quorum queue set the x-queue-type queue argument to quorum
(the default is classic). This argument must be provided by a client
at queue declaration time; it cannot be set or changed using a policy.
This is because policy definition or applicable policy can be changed dynamically but
queue type cannot. It must be specified at the time of declaration.
Declaring a queue with an x-queue-type argument set to quorum will declare a quorum queue with
up to three members (default group size),
one per each cluster node.
For example, a cluster of three nodes will have three members, one on each node. In a cluster of five nodes, three nodes will have one member each but two nodes won't host any members.
After declaration a quorum queue can be bound to any exchange just as any other RabbitMQ queue.
If declaring using management UI, queue type must be specified using the queue type drop down menu.
Client Operations
The following operations work the same way for quorum queues as they do for classic queues:
- Consumption (subscription)
- Consumer acknowledgements (keep QoS Prefetch Limitations in mind)
- Cancellation of consumers
- Purging of queue messages
- Queue deletion
With some queue operations there are minor differences:
- Declaration (covered above)
- Setting QoS prefetch for consumers
Group Size and Membership Management
When a quorum queue is declared, an initial number of members (its "group size") must be configured. RabbitMQ defaults this to 3 which is the practical minimum number of members to provide high availability.
The members of a quorum queue will never share a RabbitMQ node so in order to declare a new 3-member quorum queue at least 2 RabbitMQ nodes need to be online at the time of declaration.
Controlling the Initial Group Size
For example, a cluster of three nodes will have three members, one on each node. In a cluster of seven nodes, three nodes will have one member each but four more nodes won't host any members of the newly declared queue.
The group size (the initial number of members) can be configured for quorum queues
using the x-quorum-initial-group-size queue argument.
The group size argument provided should be an integer that is greater than zero and smaller or
equal to the currently configured RabbitMQ cluster size.
The minimum value of x-quorum-initial-group-size that makes practical sense
is three which will support the failure of 1 RabbitMQ node.
As for RabbitMQ cluster sizes it is highly recommended for the quorum queue group size to be an odd number.
See the Fault Tolerance and Minimum Number of Members Online section for further details on the quorum semantics.
NB: if a RabbitMQ node is unavailable during a declaration and it is chosen to host a quorum queue member this member will be started the next time the node is started.
Managing Members
Replicas of a quorum queue are explicitly managed by the operator. When a new node is added to the cluster, it will host no quorum queue members unless the operator explicitly adds a member to a quorum queue or a set of quorum queues.
When a node has to be decommissioned (permanently removed from the cluster), the
forget_cluster_node command will automatically attempt to remove all quorum queue
members on the decommissioned node. Alternatively the shrink command below can be used ahead of
node removal to move any members to a new node.
Also see Continuous Membership Reconciliation for a more automated way to grow quorum queues.
Several CLI commands are provided to perform the above operations:
rabbitmq-queues add_member [-p <vhost>] <queue-name> <node>
rabbitmq-queues delete_member [-p <vhost>] <queue-name> <node>
rabbitmq-queues grow <node> <all | even> [--vhost-pattern <pattern>] [--queue-pattern <pattern>]
rabbitmq-queues shrink <node> [--errors-only]
To successfully add and remove members a quorum of members in the queue must be available because membership changes are treated as queue state changes.
Care needs to be taken not to accidentally make a queue unavailable by losing the quorum whilst performing maintenance operations that involve membership changes.
When replacing a cluster node, it is safer to first add a new node, grow any quorum queues that need a member on the new node and then decommission the node it replaces.
Queue Leader Location
All operations (state changes) on a quorum queue are sent to a primary member called a leader which in turn replicates the operations to the remaining members, called followers.
To avoid some nodes in a cluster hosting the majority of queue leader members and thus handling most of the load, it may be beneficial if queue leaders are reasonably evenly distributed across cluster nodes.
When a new quorum queue is declared, the set of nodes that will host its members is randomly picked, but will always include the node the client that declares the queue is connected to.
Which member becomes the initial leader can be controlled using three options:
- Setting the
queue-leader-locatorpolicy key (recommended) - By defining the
queue_leader_locatorkey in the configuration file (recommended) - Using the
x-queue-leader-locatoroptional queue argument
Supported queue leader locator values are
client-local: Pick the node the client that declares the queue is connected to. This is the default value.balanced: If there are overall less than 1000 queues (classic queues, quorum queues, and streams), pick the node hosting the minimum number of quorum queue leaders. If there are overall more than 1000 queues, pick a random node.
Rebalancing Members
Once declared or after a cluster restart, the RabbitMQ quorum queue leaders may be unevenly distributed across the RabbitMQ cluster.
To re-balance use the rabbitmq-queues rebalance command.
It is important to know that this does not change the nodes which the quorum queues span. To modify the membership instead see managing members.
# rebalances all quorum queues
rabbitmq-queues rebalance quorum
It is possible to rebalance a subset of queues selected by name:
# rebalances a subset of quorum queues
rabbitmq-queues rebalance quorum --queue-pattern "orders.*"
or quorum queues in a particular set of virtual hosts:
# rebalances a subset of quorum queues
rabbitmq-queues rebalance quorum --vhost-pattern "production.*"
Continuous Membership Reconciliation (CMR)
The continuous membership reconciliation (CMR) feature exists in addition to, and not as a replacement for, explicit member management. In certain cases where nodes are permanently removed from the cluster, explicitly removing quorum queue members may still be necessary.
In addition to controlling quorum queue membership by using the initial target size and explicit member management, nodes can be configured to automatically try to grow the quorum queue membership to a configured target group size by enabling the continuous membership reconciliation feature.
When activated, every quorum queue leader will periodically check its current membership group size (the number of configured members), and compare it with the target value.
If a queue is below the target value, RabbitMQ will attempt to grow the queue onto the available nodes that do not currently host members of said queue, if any, up to the target value.
When is Continuous Membership Reconciliation Triggered?
The default reconciliation interval is 60 minutes. In addition, automatic reconciliation is triggered by certain events in the cluster, such as an addition of a new node, or permanent node removal, or a quorum queue-related policy change.
Note that a node or quorum queue member failure does not trigger automatic membership reconciliation.
If a node is failed in an unrecoverable way and cannot be brought back, it must be explicitly removed from the cluster
or the operator must opt-in and enable the quorum_queue.continuous_membership_reconciliation.auto_remove setting.
This also means that upgrades do not trigger automatic membership reconciliation since nodes are expected to come back and only a minority (often just one) node is stopped for upgrading at a time.
CMR Configuration
Via rabbitmq.conf
rabbitmq.conf configuration key | Description |
|---|---|
| Enables or disables continuous membership reconciliation.
|
| The target member count (group size) for queue members.
|
| Enables or disables automatic removal of member nodes that are no longer part of the cluster, but still a member of the quorum queue.
|
| The default evaluation interval in milliseconds.
|
| The reconciliation delay in milliseconds, used when a trigger event occurs, for example, a node is added or removed from the cluster or an applicable policy changes. This delay will be applied only once, then the regular interval will be used again.
|
Policy Keys
| Policy key | Description |
|---|---|
| Defines the target member count (group size) for matching queues. This policy can be set by users and operators.
|
| Optional arguments key | Description |
|---|---|
| Defines the target member count (group size) for matching queues. This key can be overridden by operator policies.
|
Quorum Queue Behaviour
A quorum queue relies on a consensus protocol called Raft to ensure data consistency and safety.
Every quorum queue has a primary member (a leader in Raft parlance) and zero or more secondary members (called followers).
A leader is elected when the cluster is first formed and later if the leader becomes unavailable.
Leader Election and Failure Handling
A quorum queue requires a quorum of the declared nodes to be available to function. When a RabbitMQ node hosting a quorum queue's leader fails or is stopped another node hosting one of that quorum queue's follower will be elected leader and resume accepting operations.
Failed and rejoining followers will automatically resume log replication at the point they left off which means there is no special "catch-up" process needed and there is no impact on leader availability as was the case with classic mirrored queues.
When a new member is added, the same log replication process will be performed and again there is little impact on the rest of the quorum queue cluster.
Fault Tolerance and Minimum Number of Members Online
Consensus systems can provide certain guarantees with regard to data safety. These guarantees do mean that certain conditions need to be met before they become relevant such as requiring a minimum of three cluster nodes to provide fault tolerance and requiring more than half of members to be available to work at all.
Failure tolerance characteristics of clusters of various size can be described in a table:
| Cluster node count | Tolerated number of node failures | Tolerant to a network partition |
|---|---|---|
| 1 | 0 | not applicable |
| 2 | 0 | no |
| 3 | 1 | yes |
| 4 | 1 | yes if a majority exists on one side |
| 5 | 2 | yes |
| 6 | 2 | yes if a majority exists on one side |
| 7 | 3 | yes |
| 8 | 3 | yes if a majority exists on one side |
| 9 | 4 | yes |
As the table above shows RabbitMQ clusters with fewer than three nodes do not benefit fully from the quorum queue guarantees. RabbitMQ clusters with an even number of RabbitMQ nodes do not benefit from having quorum queue members spread over all nodes. For these systems the quorum queue size should be constrained to a smaller uneven number of nodes.
Performance tails off quite a bit for quorum queue node sizes larger than 5.
We do not recommend running quorum queues on more than 7 RabbitMQ nodes. The
default quorum queue size is 3 and is controllable using the
x-quorum-initial-group-size queue argument.
Data Safety
Quorum queues are designed to provide data safety under network partition and failure scenarios. A message that was successfully confirmed back to the publisher using the publisher confirms feature should not be lost as long as at least a majority of RabbitMQ nodes hosting the quorum queue are not permanently made unavailable.
Generally quorum queues favours data consistency over availability.
Quorum queues cannot provide any safety guarantees for messages that have not been confirmed to the publisher. Such messages could be lost "in flight", in an operating system buffer or otherwise fail to reach the target node or the queue leader.
Quorum queues pass a refactored and more demanding version of the original Jepsen test. This ensures they behave as expected under network partitions and failure scenarios. The new test runs continuously to spot possible regressions and is enhanced regularly to test new features (e.g. dead lettering).
Availability
A quorum queue should be able to tolerate a minority of queue members becoming unavailable with no or little effect on availability.
Note that depending on the partition handling strategy used RabbitMQ may restart itself during recovery and reset the node but as long as that does not happen, this availability guarantee should hold true.
For example, a queue with three members can tolerate one node failure without losing availability. A queue with five members can tolerate two, and so on.
If a quorum of nodes cannot be recovered (say if 2 out of 3 RabbitMQ nodes are permanently lost) the queue is permanently unavailable and will need to be force deleted and recreated.
Performance Characteristics
Quorum queues have been optimized further in RabbitMQ 4.1.x and now feature lower memory footprints and improved consumer delivery rates, parallelism under peak load.
Quorum queues are designed to trade latency for throughput and have been tested in 3, 5 and 7 node configurations with several different message sizes.
In scenarios using both consumer acks and publisher confirms quorum queues have been observed to have superior throughput to classic mirrored queues (deprecated in 2021, removed in 2024 for RabbitMQ 4.0). For example, take a look at these benchmarks with 3.10 and another with 3.12.
As quorum queues persist all data to disks before doing anything it is recommended to use the fastest disks possible and certain Performance Tuning settings.
Quorum queues also benefit from consumers using higher prefetch values to ensure consumers aren't starved whilst acknowledgements are flowing through the system and allowing messages to be delivered in a timely fashion.
Due to the disk I/O-heavy nature of quorum queues, their throughput decreases as message sizes increase.
Quorum queue throughput is also affected by the number of members. The more members a quorum queue has, the lower its throughput generally will be since more work has to be done to replicate data and achieve consensus.
Migrating from RabbitMQ 3.13.x with Mirrored Classic Queues to Quorum Queues Using Blue-Green Deployment
rabbitmqadmin v2 provides commands for automating migration from 3.13.x clusters
that use classic mirrored queues to quorum queues using the Blue-Green Deployment strategy.
See Using Blue-Green Upgrade Strategy to Migrate from Classic Mirrored Queues to Quorum Queues.
Configurable Settings
There are a few new configuration parameters that can be tweaked using the advanced config file.
Note that all settings related to resource footprint are documented in a separate section.
The ra application (which is the Raft library that quorum
queues use) has its own set of tunable parameters.
The rabbit application has several quorum queue related configuration items available.
advanced.config configuration key | Description | Default value |
|---|---|---|
| rabbit.quorum_cluster_size | Sets the default quorum queue cluster size (can be over-ridden by the | 3 |
| rabbit.quorum_commands_soft_limit | This is a flow control related parameter defining the maximum number of unconfirmed messages a channel accepts before entering flow. The current default is configured to provide good performance and stability when there are multiple publishers sending to the same quorum queue. If the applications typically only have a single publisher per queue this limit could be increased to provide somewhat better ingress rates. | 32 |
| rabbit.consumer_timeout | Global default consumer timeout in milliseconds for all quorum queues.
Can be overridden by policy or queue argument. Set to | undefined |
| rabbit.consumer_disconnected_timeout | Timeout in milliseconds for returning messages when a consumer's node becomes unreachable due to a network partition. After this timeout, the messages are returned to the queue. | 60000 |
In rabbitmq.conf, these can be configured as:
consumer_timeout = 1800000
consumer_disconnected_timeout = 60000
Example of a Quorum Queue Configuration
The following rabbitmq.conf example shows both legacy and new configuration options:
quorum_queue.initial_cluster_size = 3
quorum_queue.commands_soft_limit = 32
consumer_timeout = 1800000
consumer_disconnected_timeout = 60000
Advanced Quorum Queue Configuration
Starting with RabbitMQ 4.3, all quorum queue Ra system parameters are explicitly configurable via rabbitmq.conf using the quorum_queue.* namespace. This allows operators to fine-tune Raft log and WAL behavior specifically for quorum queues without affecting other Raft-based features (like streams or Khepri).
These configuration options are for advanced use cases and should typically not be changed by users unless advised to do so by RabbitMQ core team members or support.
rabbitmq.conf Key | Description | Default Value |
|---|---|---|
quorum_queue.segment_max_size_bytes | Maximum size of a Raft log segment file | 64000000 (64 MB) |
quorum_queue.segment_max_entries | Maximum number of entries in a Raft log segment file | 4096 |
quorum_queue.wal_max_size_bytes | Maximum size of the Write-Ahead Log | 536870912 (512 MB) |
quorum_queue.wal_max_entries | Maximum number of entries in the Write-Ahead Log | 500000 |
quorum_queue.wal_max_batch_size | Maximum batch size for WAL writes | 4096 |
quorum_queue.wal_compute_checksums | Whether to compute checksums for WAL entries | true |
quorum_queue.segment_compute_checksums | Whether to compute checksums for segment entries | true |
quorum_queue.max_append_entries_rpc_batch_size | Maximum batch size for append entries RPCs | 16 |
quorum_queue.compress_mem_tables | Whether to compress memory tables | true |
quorum_queue.snapshot_chunk_size | Chunk size for snapshot transfers | 1000000 (1 MB) |
Options to Relax Property Equivalence Checks
When a client redeclares a queue, RabbitMQ nodes perform a property equivalence checks. If some properties are not equivalent, the declaration will fail with a channel error.
In environment where applications explicitly set the type of the queue via the x-queue-type argument
and cannot be quickly updated and/or redeployed, the equivalence check for x-queue-type can be ignored
with an opt-in setting:
quorum_queue.property_equivalence.relaxed_checks_on_redeclaration = true
If quorum_queue.property_equivalence.relaxed_checks_on_redeclaration is set to true,
the 'x-queue-type' header will be ignored (not compared for equivalence)
for queue redeclaration.
This can simplify upgrades of applications that explicitly set 'x-queue-type' to 'classic' for historical reasons but do not set any other properties that may conflict or significantly change queue behavior and semantics, such as the 'exclusive' field.
Resource Use
Quorum queues have been optimized further in RabbitMQ 4.1.x and now feature lower memory footprints and improved consumer delivery rates, parallelism under peak load.
Quorum queues are optimised for data safety and performance. Each quorum queue process maintains an in-memory index of the messages in the queue, which requires at least 32 bytes of metadata for each message (more, if the message was returned or has a TTL set). A quorum queue process will therefore use at least 1MB for every 30000 messages in the queue (message size is irrelevant). You can perform back-of-the-envelope calculations based on the number of queues and expected or maximum number of messages in them). Keeping the queues short is the best way to maintain low memory usage. Setting the maximum queue length for all queues is a good way to limit the total memory usage if the queues become long for any reason.
How Memory, WAL and Segments Files Interact
Quorum queues on a given node share a write-ahead-log (WAL) for all operations. The WAL contains a limited number of recent operations on the queue. WAL entries are stored both in memory and written to disk. When the current WAL file reaches a predefined limit, it is flushed to segment files on disk for each quorum queue member on a node and the system will begin to release the memory used by that batch of log entries.
The segment files are then compacted over time as consumers acknowledge deliveries. Compaction is the process that reclaims disk space.
The WAL file size limit at which it is flushed to disk can be controlled:
# Flush current WAL file to a segment file on disk once it reaches 64 MiB in size
raft.wal_max_size_bytes = 64000000
The value defaults to 512 MiB. This means that during steady load, the WAL table memory footprint can reach 512 MiB.
Because memory is not guaranteed to be deallocated instantly by the runtime, we recommend that the RabbitMQ node is allocated at least 3 times the memory of the effective WAL file size limit. More will be required in high-throughput systems. 4 times is a good starting point for those.
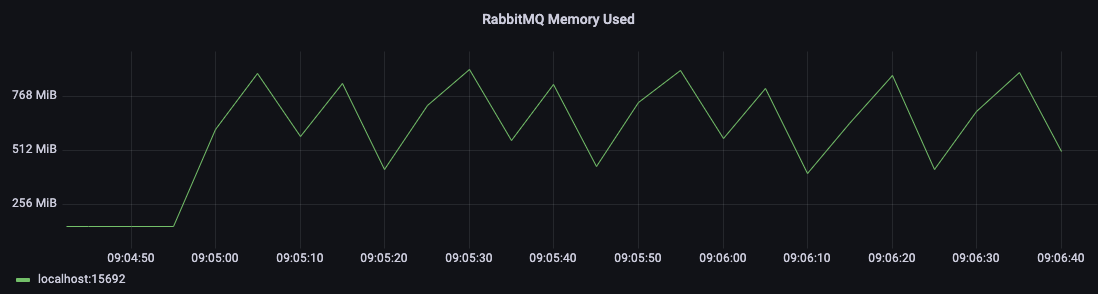
The memory footprint pattern of quorum queues will typically look like this:
Log Compaction
Quorum queues maintain a log of all operations (enqueues, acknowledgements, etc.). Over time, as consumers acknowledge messages, much of this log data becomes obsolete and can be reclaimed.
Starting with RabbitMQ 4.3, quorum queues can now reclaim disk space even if:
- Messages are acknowledged out of order
- Some messages are retained in the queue for extended periods (e.g., by a slow consumer or held as a delayed retry)
- Acknowledgements arrive at different rates
Previously, a single unacknowledged message could prevent the log from being truncated, leading to unbounded disk growth. With the new log compaction mechanism in Ra v3, the state machine tracks a list of live raft indexes (messages that are still unacknowledged or otherwise needed). When a snapshot is taken, the log undergoes compaction:
- Minor Compaction: Runs after every snapshot. It identifies and deletes entire segment files that contain zero live entries.
- Major Compaction: Runs periodically in the background. It consolidates multiple sparse segments by copying only the remaining live entries into new, smaller segments, and deleting the old ones.
This allows the data for acknowledged messages to be omitted from the snapshot and removed from disk, reducing both snapshot size and write amplification, and safely reclaiming disk space.
For more technical details on the compaction architecture, see the Ra Log Compaction documentation.
Snapshot Throttling
To prevent excessive disk I/O, snapshot frequency is intelligently throttled based on the write-ahead log (WAL) fill ratio. This ensures roughly one snapshot per queue per WAL cycle, optimizing performance for both shallow, fast-flowing queues and deep queues.
Disk Space
In environments with heavy quorum queue usage and/or large messages flowing through them, it is very important to overprovision disk space, that is, have the extra spare capacity. This follows the general recommendation for storage for modern release series.
With large messages (say, 1 MiB and higher), quorum queue disk footprint can be large. While RabbitMQ 4.3 significantly improves log compaction, the removal of obsolete data from segment files still requires background processing.
This leads to several recommendations:
- In environments with heavy quorum queue usage and/or large messages flowing through them, it is very important to overprovision disk space, that is, have the extra spare capacity
- While quorum queues no longer strictly require consumers to acknowledge messages in a timely manner to prevent unbounded disk growth, a reasonably low delivery acknowledgement timeout is still recommended to reduce the write amplification overhead of copying unacknowledged messages during major compaction
- Consider using delayed retry to manage message processing with backoff, reducing rapid redelivery loops
- Larger messages can be stored in a blob store as an alternative, with relevant metadata being passed around in messages flowing through quorum queues
Repeatedly Requeued Deliveries (Deliver-Requeue Loops)
Repeated requeues of the same message (where a consumer continuously rejects or nacks a message with the requeue flag set to true) can happen when a consumer encounters a transient error or is unable to process a message. RabbitMQ provides safeguards to prevent this pattern from causing issues.
Built-in Protections
Starting with RabbitMQ 4.0, quorum queues enforce a default delivery-limit of 20 based on delivery-count. When a message's delivery count exceeds this limit, it is either dropped or dead-lettered (if a DLX is configured).
However, it's important to note that requeue operations may not increment the delivery count. Requeues without incrementing the counter (such as returns via nack or AMQP 1.0 modify with delivery_failed=false) will not count toward the delivery limit, allowing unlimited requeue loops for application-level routing logic. Only actual failed redeliveries (such as via reject, AMQP 1.0 modify with delivery_failed=true, or when a channel/session is terminated with pending unacknowledged messages) increment the delivery count.
Recommended Approach: Delayed Retry
Rather than relying on the delivery limit to catch problematic messages, use delayed retry to implement intelligent backoff:
- Automatic Backoff: Delay is applied linearly based on delivery count, reducing server load during transient errors
- Configurable Behavior: Choose to delay all returns, only failed deliveries, or only explicit returns
- Better Observability: Monitor delayed message counts in the Management UI to identify problematic consumers
- Flexible Recovery: Use the timeout mechanism or retry strategies to recover gracefully
This prevents rapid requeue loops from overwhelming the queue and allows the log to be compacted efficiently.
Message Return Behavior (RabbitMQ 4.3+)
Starting with RabbitMQ 4.3, the delivery limit is explicitly based on delivery-count rather than acquired-count. This means:
- Unlimited explicit returns (via
nackor AMQP 1.0modifywithdelivery_failed=false) are allowed without counting toward the delivery limit - Only actual redeliveries (via
reject, AMQP 1.0modifywithdelivery_failed=true, or channel/session termination with pending messages) increment the counter - This provides flexibility for application-level message routing and processing logic
Disabling the Delivery Limit
The default delivery limit can be disabled by setting x-delivery-limit=-1 as a queue argument:
x-delivery-limit = -1
This is only recommended for compatibility with RabbitMQ 3.13.x behavior in rare cases. Modern deployments should use delayed retry instead.
Increased Atom Use
The internal implementation of quorum queues converts the queue name into an Erlang atom. If queues with arbitrary names are continuously created and deleted it may threaten the long term stability of the RabbitMQ system if the size of the atom table reaches the default limit of 5 million.
While quorum queues were not designed to be used in high churn environments (non-mirrored classic queues are the optimal choice for those), the limit can be increased if really necessary.
See the Runtime guide to learn more.
Performance Tuning
Quorum queues have been optimized further in RabbitMQ 4.1.x and now feature lower memory footprints and improved consumer delivery rates, parallelism under peak load.
This section aims to cover a couple of tunable parameters that may increase throughput of quorum queues for some workloads. Other workloads may not see any increases, or observe decreases in throughput, with these settings.
Use the values and recommendations here as a starting point and conduct your own benchmark (for example, using PerfTest) to conclude what combination of values works best for a particular workloads.
Tuning: Raft Segment File Entry Count
This tuning parameter is no longer recommended. Segments now have a size limit (controlled by quorum_queue.segment_max_size_bytes, which defaults to 64000000 bytes or 64 MB) which is the primary factor in segment management. Increasing the number of entries per segment can negatively impact log compaction efficiency.
In modern RabbitMQ versions, the segment file size is the primary limiting factor for performance and compaction. Manually tuning the entry count can cause segments to become very large before being eligible for compaction, potentially slowing down the removal of obsolete data.
If you need to control the maximum size of Raft log segment files for quorum queues, adjust the quorum_queue.segment_max_size_bytes configuration instead.
If you are currently using custom raft.segment_max_entries settings in production, consider removing them and relying on the default values and size-based limits.
Tuning: Linux Readahead
In addition, the aforementioned workloads with a higher rate of small messages can benefit from
a higher readahead, a configurable block device parameter of storage devices on Linux.
To inspect the effective readahead value, use blockdev --getra
and specify the block device that hosts RabbitMQ node data directory:
# This is JUST AN EXAMPLE.
# The name of the block device in your environment will be different.
#
# Displays effective readahead value device /dev/sda.
sudo blockdev --getra /dev/sda
To configure readahead, use blockdev --setra for
the block device that hosts RabbitMQ node data directory:
# This is JUST AN EXAMPLE.
# The name of the block device in your environment will be different.
# Values between 256 and 4096 in steps of 256 are most commonly used.
#
# Sets readahead for device /dev/sda to 4096.
sudo blockdev --setra 4096 /dev/sda